 后端基础类库说明
后端基础类库说明
# 基础工具类
# 一 、基础工具类
Hutool 一个 Java 基础工具类,对文件、流、加密解密、转码、正则、线程、XML 等 JDK 方法进行封装,组成各种 Util 工具类。 项目中已经引入了 hutool 相关的 jar, 可直接使用相关的方法
👉🏻 工具类官方手册(opens new window) (opens new window)
| 模块 | 介绍 |
|---|---|
| hutool-aop | JDK 动态代理封装,提供非 IOC 下的切面支持 |
| hutool-bloomFilter | 布隆过滤,提供一些 Hash 算法的布隆过滤 |
| hutool-cache | 简单缓存实现 |
| hutool-core | 核心,包括 Bean 操作、日期、各种 Util 等 |
| hutool-cron | 定时任务模块,提供类 Crontab 表达式的定时任务 |
| hutool-crypto | 加密解密模块,提供对称、非对称和摘要算法封装 |
| hutool-db | JDBC 封装后的数据操作,基于 ActiveRecord 思想 |
| hutool-dfa | 基于 DFA 模型的多关键字查找 |
| hutool-extra | 扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等) |
| hutool-http | 基于 HttpUrlConnection 的 Http 客户端封装 |
| hutool-log | 自动识别日志实现的日志门面 |
| hutool-script | 脚本执行封装,例如 Javascript |
| hutool-setting | 功能更强大的 Setting 配置文件和 Properties 封装 |
| hutool-system | 系统参数调用封装(JVM 信息等) |
| hutool-json | JSON 实现 |
| hutool-captcha | 图片验证码实现 |
| hutool-poi | 针对 POI 中 Excel 和 Word 的封装 |
| hutool-socket | 基于 Java 的 NIO 和 AIO 的 Socket 封装 |
| hutool-jwt | JSON Web Token (JWT)封装实现 |
# 二、Redis 工具类
全局操作 Redis 均使用 RedisTemplate,避免连接泄漏
理论上 RedisTemplate 支持 Redis 的全部命令,比市面上自己封装 Jedis 等强大、优雅太多
👉🏻 常用方法教程(opens new window) (opens new window)
@Service
public class DemoService {
@Autowired
private RedisTemplate redisTemplate;
public void test() {
// opsForValue set get value
redisTemplate.opsForValue().set("k1", "v1");
Object v1 = redisTemplate.opsForValue().get("k1");
// opsForValue set value 10秒钟 过期
redisTemplate.opsForValue().set("k2", "v2", 10, TimeUnit.SECONDS);
// opsForHash set get value
redisTemplate.opsForHash().put("k3", "h1", "v3");
redisTemplate.opsForHash().get("k3", "h1");
// 删除某个key
redisTemplate.delete("k1");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 三、Spring 工具类
// 根据 bean 名称获取bean
Bean bean = SpringContextHolder.getBean("bean名称");
// 根据 bean class 获取bean
Bean bean = SpringContextHolder.getBean(Bean.class");
// 发送 spring Event
SpringContextHolder.publishEvent(eventObj)
2
3
4
5
6
7
8
# swagger 接口文档使用
# 接入调试
- 访问 swagger-ui 页面
访问
http://mbm-gateway:8888/swagger-ui.html1打开 swagger 页面。
请求入口必须是 mbm-gateway:8888 这种形式, 而不是 ip:8888 ,不然跨域。
- 模拟登陆
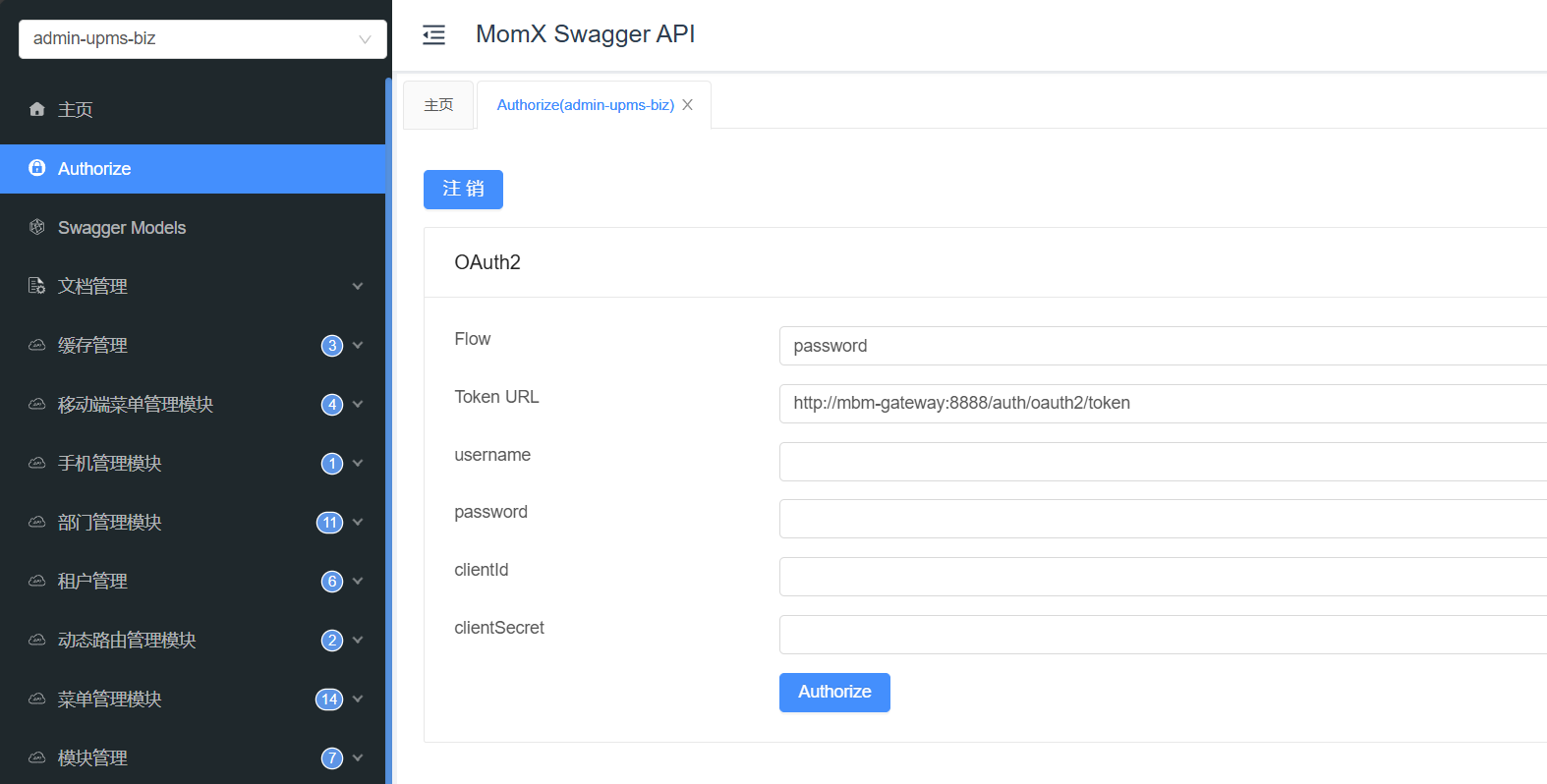
填写客户端信息
username: admin password: JHsnKqdw [123456加密后的密文] client_id: mom client_secret : mom1
2
3
4
# 新服务接入
服务添加依赖
<dependency> <groupId>com.sie.mbm.mom</groupId> <artifactId>framework-swagger</artifactId> </dependency>1
2
3
4目标服务开启 OpenApi
- 在应用主类中增加
@EnableOpenApi注解 并且填写当前应用的网关请求前缀
@EnableOpenApi("admin") public class AdminApplication {}1
2- 在应用主类中增加
特别注意
Controller 接口上边必须增加 @SecurityRequirement(name = HttpHeaders.AUTHORIZATION)
@Tag(description = "connect", name = "开放互联") @SecurityRequirement(name = HttpHeaders.AUTHORIZATION) public class ConnectController {}1
2
3常用注解
详细注解可以参考:https://blog.csdn.net/weixin_44768189/article/details/115055784(opens new window) (opens new window)
# swagger 使用常见问题
服务列表没有目标服务
- 检查 nacos 服务列表检查服务状态是否正常
- 重点: 访问 swagger 右上角服务列表没有展示新增服务,请确认动态路由 是否已经配置, 且动态路由 配置路由 ID 和 nacos 服务名称保持一致
如何选择性展示服务
默认所有配置在路由的服务都会被服务列表加载,在 nacos `admin-gateway-dev.yml```中配置 ignore.swagger-providers 属性来屏蔽掉不希望生成 swaager 文档的微服务。
切换 swagger 分组文档页面报错
出现这个问题要么是你对应的服务没有启动,要么是你访问的服务还没有启动完毕,如果还没启动完毕的话,不妨等个十几二十秒再进行访问
刷新页面后认证失效?
官方 UI 比较蠢萌,虽然提供了 Oauth2.0 的认证功能,但是没有存储的措施,所以刷新页面后相关参数就会丢失。
认证过程中出现
Auth ErrorError: Upgrade Required?这个不用怀疑,原因一般不外乎三个。
一、用户名或密码错误
可以打开谷歌开发者工具,观察 request 详情和 response 详情以及返回的状态码,如果是 426 的话,就证明获取用户信息的时候失败了,可以判断是作为缓存中间件的 redis 并没有启动,那么只要启动 redis,另一个原因是 redis 中有脏数据,这个时候清空 redis 即可。清空的具体步骤如下:
windows 平台下可以打开 redis-cli.exe,然后执行
flushdb或者flushall命令即可。二、使用了需要验证码的客户端
除了上面的原因,还有可能返回 428 的状态码,而会出现这个问题就是使用了需要验证码的客户端。
三、跨域
排除所有不可能,剩下的那个不管多不可思议,都是事实真相。除开这两个原因,还有可能会出问题的,只有一种情况,那就是出现了跨域问题。
确定是否使用
http://mbm-gateway:8888/swagger-ui.html访问,而非 IP 访问
# 系统多租户使用
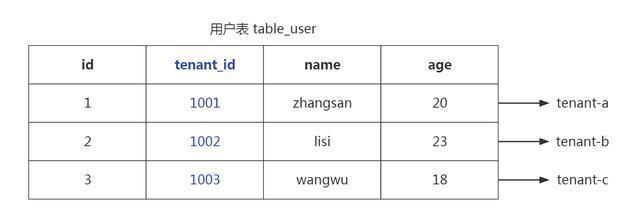
租户功能说明
系统提供多租户功能是基于租户共享同一个 Database、同一个 Schema,但在表中通过 TenantID 区分租户的数据的模式。
增删改查方法时,会自动维护租户 ID,不需要手动处理,即可实现通过租户 ID 过滤的效果
# 目标表中预留 tenant_id 字段.
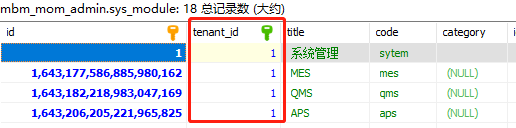
# 在配置中心维此表即可
# 在对应微服务模块的 nacos 配置
mom:
tenant:
column: tenant_id
tables:
- sys_user
2
3
4
5
6
# 实现原理
参考 mybatis-plus 的多租户 SQL 解析器 (opens new window)
上下传递的前端传递的租户 ID,全局拦截器拦截传递的租户 ID 放到 theadlocal 中 如果为空默认值为1
public class TenantContextHolderFilter extends GenericFilterBean {
private final static String UNDEFINED_STR = "undefined";
@Override
@SneakyThrows
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String headerTenantId = request.getHeader(CommonConstants.TENANT_ID);
String paramTenantId = request.getParameter(CommonConstants.TENANT_ID);
log.debug("获取header中的租户ID为:{}", headerTenantId);
if (StrUtil.isNotBlank(headerTenantId) && !StrUtil.equals(UNDEFINED_STR, headerTenantId)) {
TenantContextHolder.setTenantId(Long.parseLong(headerTenantId));
}
else if (StrUtil.isNotBlank(paramTenantId) && !StrUtil.equals(UNDEFINED_STR, paramTenantId)) {
TenantContextHolder.setTenantId(Long.parseLong(paramTenantId));
}
else {
TenantContextHolder.setTenantId(CommonConstants.TENANT_ID_1);
}
filterChain.doFilter(request, response);
TenantContextHolder.clear();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
theadlocal 是跨线程传递租户 ID 这里使用的是 TransmittableThreadLocal (阿里巴巴开源),非常方便
TransmittableThreadLocal (opens new window)
public class TenantContextHolder {
private final ThreadLocal<Long> THREAD_LOCAL_TENANT = new TransmittableThreadLocal<>();
}
2
3
# 如何强制切换租户
-在增删改过程中请勿对 实体的 tenant 字段手动赋值,不然报错
正确方式在调用 mapper 时候,调用 如下方法即可。
TenantContextHolder.setTenantId(tenant);
示例代码
/**
* 以某个租户的身份运行
* @param tenant 租户ID
* @param func
*/
public void runAs(Long tenant, RunAs<Long> func) {
final Long pre = TenantContextHolder.getTenantId();
try {
log.trace("TenantBroker 切换租户{} -> {}", pre, tenant);
TenantContextHolder.setTenantId(tenant);
func.run(tenant);
}
catch (Exception e) {
throw new TenantBrokerExceptionWrapper(e.getMessage(), e);
}
finally {
log.trace("TenantBroker 还原租户{} <- {}", pre, tenant);
TenantContextHolder.setTenantId(pre);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 如何跳过租户过滤
- 在调用 Mapper 的方法之前,指定跳过
TenantContextHolder.setTenantSkip()
- 代码示例
public void test(){
//强制不走租户过滤
TenantContextHolder.setTenantSkip()
//查询
}
2
3
4
5
# 本地文件系统使用
# 配置文件
file:
bucketName: test # 上文创建的桶名称
local:
enable: true
base-path: /data
2
3
4
5
# 代码使用
<!--文件系统-->
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-oss</artifactId>
</dependency>
2
3
4
5
# 注入使用
@Autowire
private FileTemplate template;
template.putObject("test", fileName, file.getInputStream());
2
3
4
# Minio 文件系统使用
# 关于 MINIO
MinIO 是一个基于 Apache License v2.0 开源协议的对象存储服务。它兼容亚马逊 S3 云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几 kb 到最大 5T 不等。(本人公司大规模生产使用,数据量 TB 级别)
# Docker 运行部署
- 注意指定 access-key secret-key ,生产注意文件目录挂载
# 9000 端口是API 通信端口, 9001 是web管理台地址
docker run -p 9000:9000 -p 9001:9001 --name minio1 \
-e "MINIO_ROOT_USER=sieroot123" \
-e "MINIO_ROOT_PASSWORD=sieroot123" \
minio/minio server /data --console-address ":9001"
2
3
4
5
# 访问验证
安装后使用浏览器访问 http://ip:9001,如果可以访问,则表示 minio 已经安装成功。
账号/密码为上边指定的 sieroot123 sieroot123
# 创建 Bucket (存储空间)
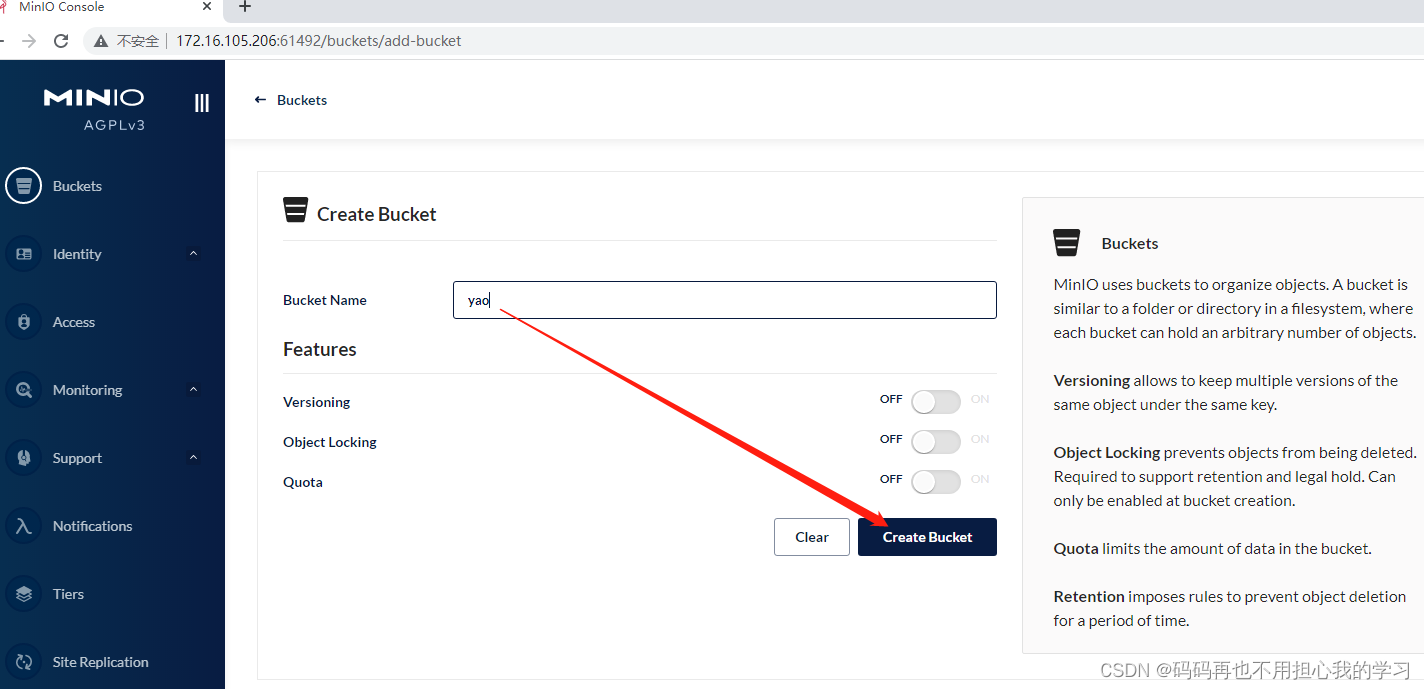
# 配置文件配置 minio 信息
file:
bucketName: yar # 上文创建的桶名称
oss:
enable: true # 开启OSS 上传
endpoint: http://IP:9000
access-key: sieroot123 # 上文创建的sieroot123
secret-key: sieroot123 # 上文创建的sieroot123
2
3
4
5
6
7
# 上传代码使用示例
<!--文件系统-->
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-oss</artifactId>
</dependency>
2
3
4
5
@Autowired
private FileTemplate template;
template.putObject("yar", fileName, file.getInputStream());
2
3
4
# 阿里云文件系统使用
阿里云对象存储 OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云存储服务,提供最高可达 99.995 % 的服务可用性。多种存储类型供选择,全面优化存储成本。
# 注册并获取参数
注册阿里云账号,并实名认证 阿里云官网
获取访问密钥
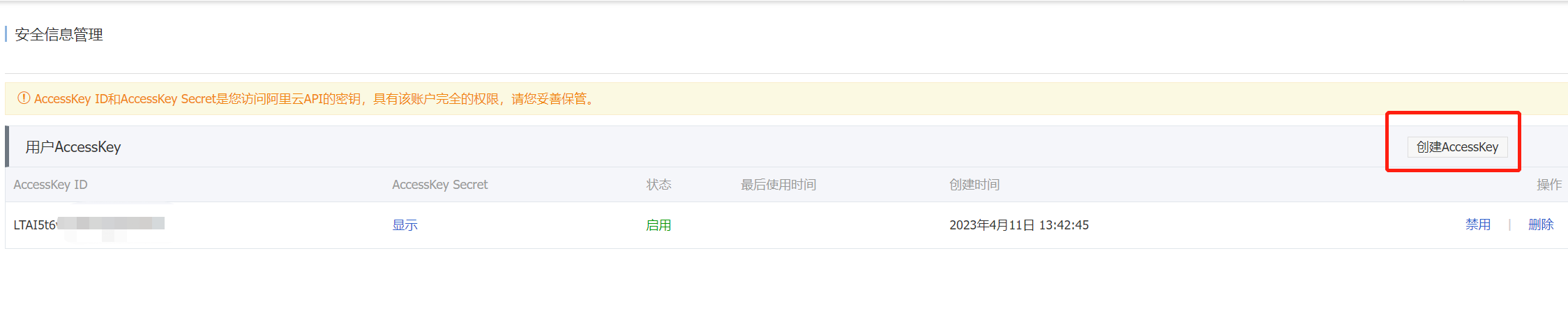
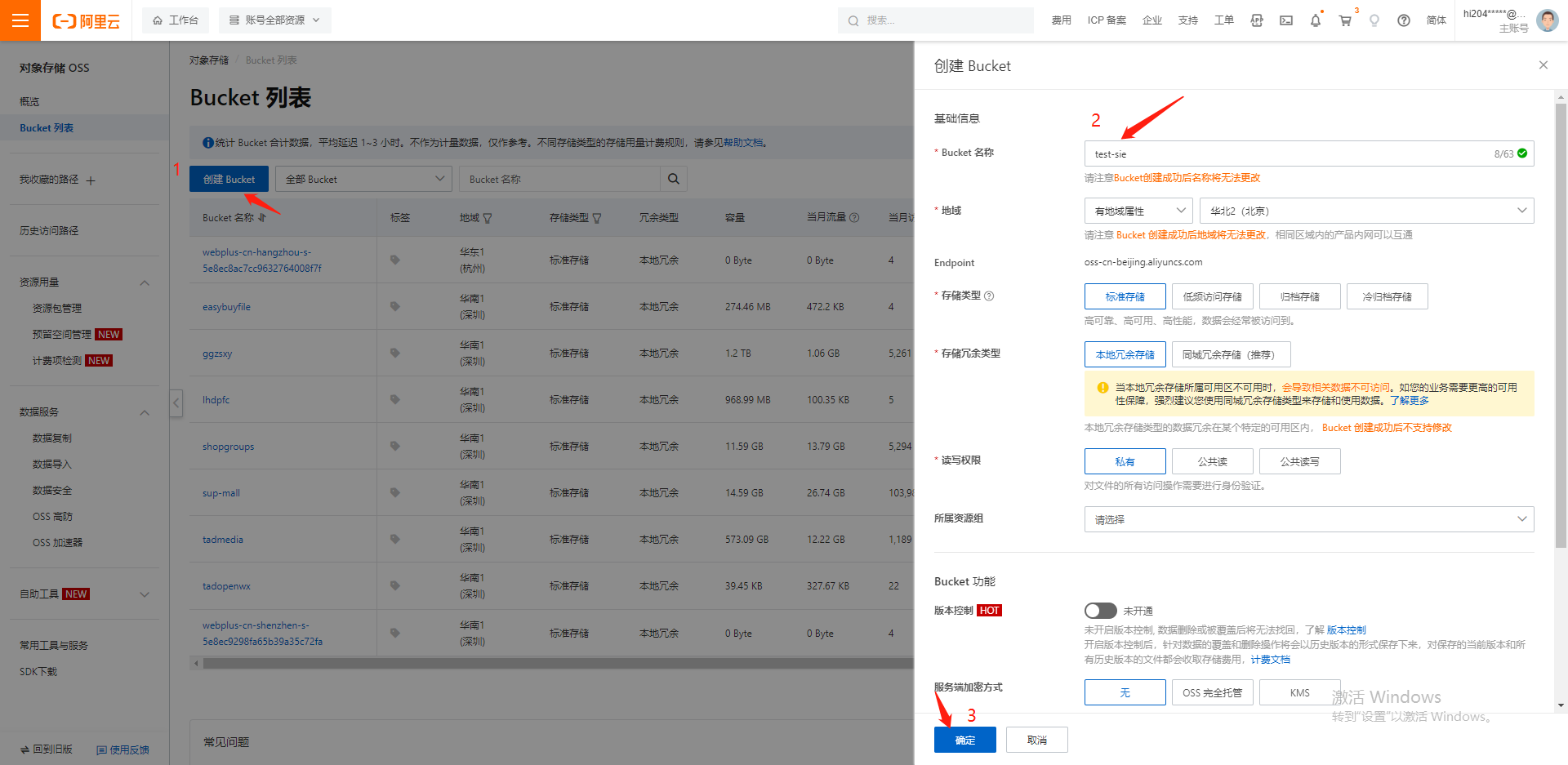
创建 bucket
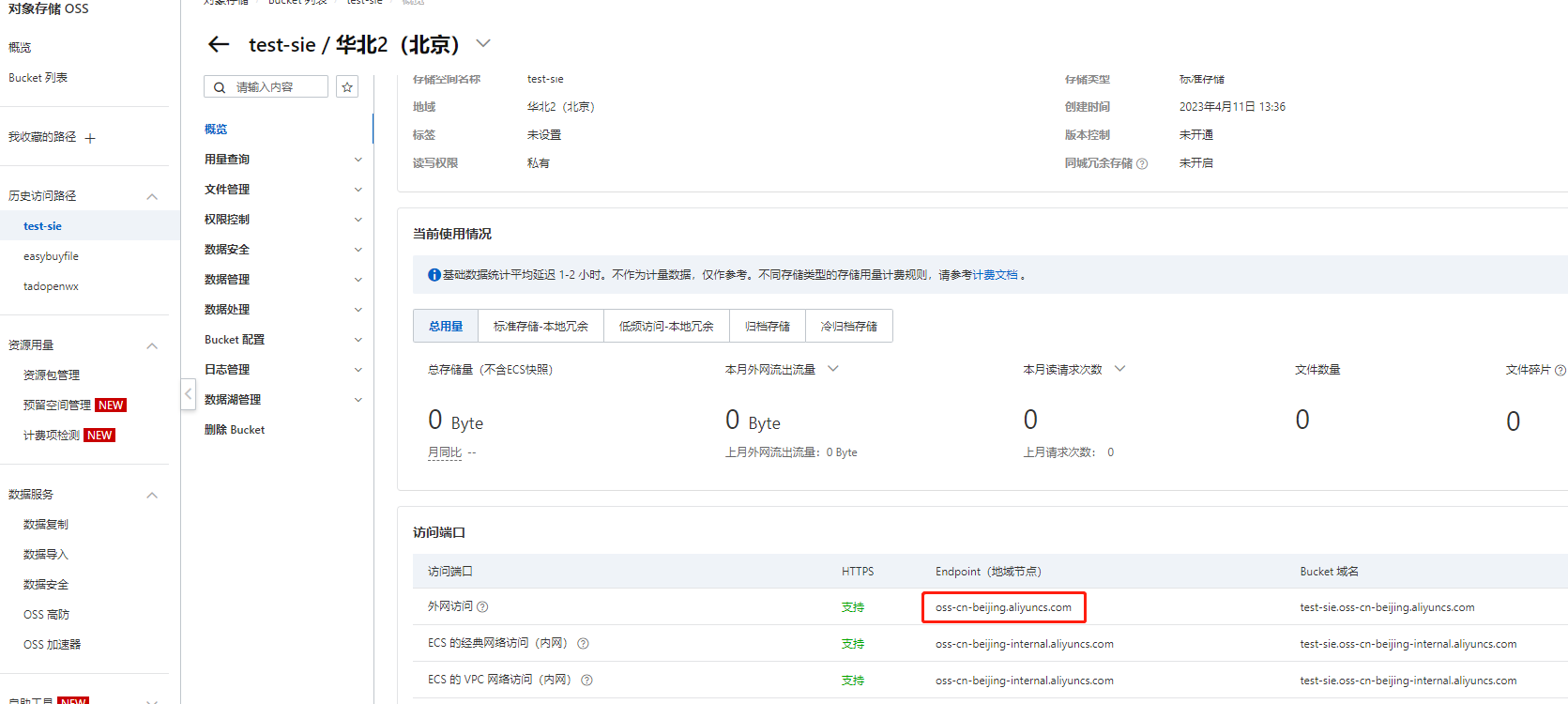
访问空间列表,获取刚创建空间基本信息
# oss 参数配置
file:
bucketName: test-sie # 上文创建的桶名称
oss:
enable: true # v4.4 开启OSS 上传
path-style-access: false #使用云OSS 需要关闭
endpoint: oss-cn-beijing.aliyuncs.com #对应上图 ③ 处配置
access-key: xxx # 上文创建的AK
secret-key: xxx # 上文创建的SK
2
3
4
5
6
7
8
# 上传代码使用示例
- 引入依赖包
<!--文件系统-->
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-oss</artifactId>
</dependency>
2
3
4
5
- 注入使用
@Autowire
private FileTemplate template;
template.putObject("test-sie", fileName, file.getInputStream());
2
3
4
# 华为云文件系统使用
华为云对象存储服务(Object Storage Service,OBS)是一个基于对象的存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力,使用时无需考虑容量限制,并且提供多种存储类型供选择,满足客户各类业务场景诉求。
# 注册并获取参数
注册阿里云账号,并实名认证 华为云官网 (opens new window)

# 创建桶
# 访问空间列表,获取刚创建空间基本信息
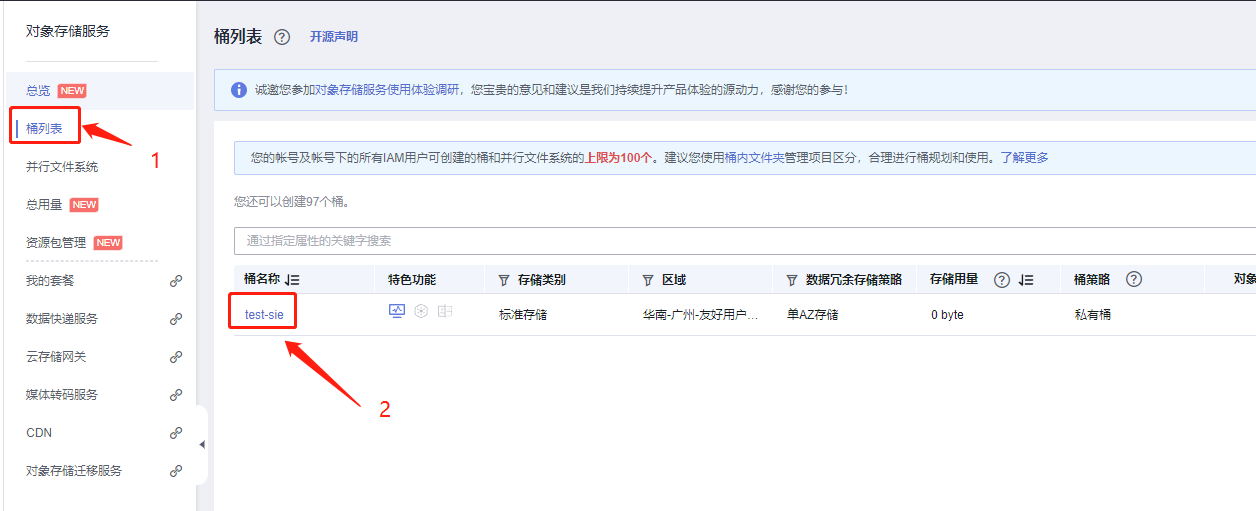
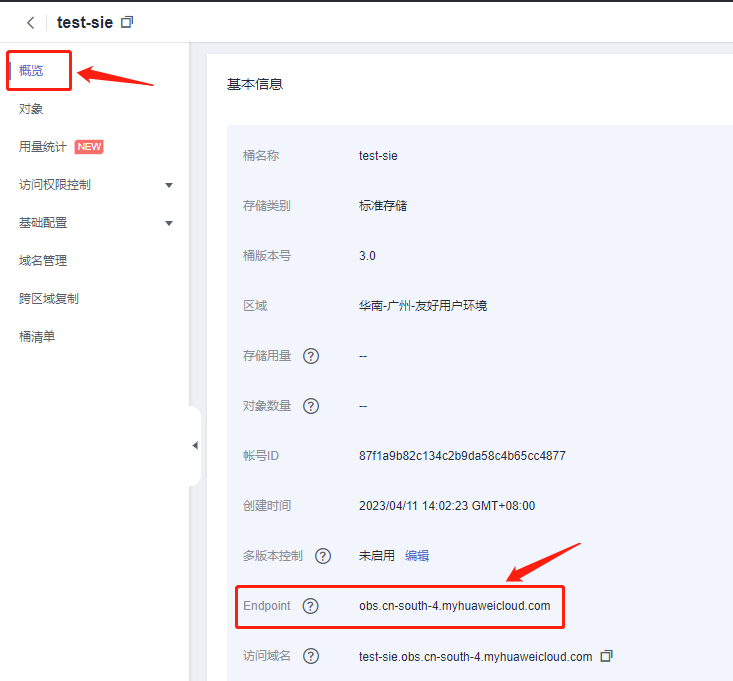
# oss参数配置
file:
bucketName: test-sie # 上文创建的桶名称
oss:
enable: true # 开启OSS 上传
path-style-access: false #使用云OSS 需要关闭
endpoint:
obs.cn-south-4.myhuaweicloud.com #对应上图配置
access-key: xxx # 上文创建的AK
secret-key: xxx # 上文创建的SK
2
3
4
5
6
7
8
9
10
# 代码使用示例
- 引入依赖包
<!--文件系统-->
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-oss</artifactId>
</dependency>
2
3
4
5
- 注入使用
@Autowire
private FileTemplate template;
template.putObject("test-sie", fileName, file.getInputStream());
2
3
4
# 系统按钮权限使用
# 如何控制菜单权限控制
在后台菜单管理中给指定菜单添加 按钮节点 需要指定 权限标志
- 例如: sys_file_add、sys_file_del、sys_file_edit 前端 CRUD 会自定生成关联按钮,只需要在 computed 生命周期注入对应的权限标识。
- 若扩展菜单 (非增删改查),则使用 vuex 保存用户的权限信息,然后通过 v-if 判断是否有权限,如果有权限就渲染这个 dom 元素。 例如:ext_btn
# 后端权限控制
接口增加
@PreAuthorize("@pms.hasPermission('权限码')")
示例
@Operation(summary = "模块查询", description = "模块查询")
@GetMapping("/{id}")
@PreAuthorize("@pms.hasPermission('admin_sysmodule_get')")
public R<SysModuleViewDTO> getById(@PathVariable("id") Long id) {
SysModule sysModule = sysModuleService.getById(id);
SysModuleViewDTO sysModuleViewDTO = SysModuleConvert.INSTANCE.convert(sysModule);
return R.ok(sysModuleViewDTO, "查询成功!");
}
2
3
4
5
6
7
8
# 原理
通过获取用户菜单列表,和请求的地址和请求方法对比判断有没有权限
/**
* 接口权限判断工具
*/
public class PermissionService {
/**
* 判断接口是否有任意xxx,xxx权限
* @param permissions 权限
* @return {boolean}
*/
public boolean hasPermission(String... permissions) {
if (ArrayUtil.isEmpty(permissions)) {
return false;
}
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
if (authentication == null) {
return false;
}
Collection<? extends GrantedAuthority> authorities = authentication.getAuthorities();
return authorities.stream().map(GrantedAuthority::getAuthority).filter(StringUtils::hasText)
.anyMatch(x -> PatternMatchUtils.simpleMatch(permissions, x));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 系统数据权限使用
# 简介说明
权限设计 = 功能权限 + 数据权限,而功能权限,在业界常常是基于 RBAC(Role-Based Access Control)的一套方案。而数据权限,则根据不同的业务场景,则权限却不尽相同,应该根据具体的场景巧妙设计; 且必须在项目开始时进行设计,不像功能权限一样,在项目结束的时候在追加。
- 【功能权限】:能做什么的问题,如增加产品。
- 【数据权限】:能看到哪些数据的问题,如只能查看本部门数据等。
# 数据权限粒度
角色管理 > 编辑 > 权限范围
- 查询全部数据
- 查询本部门数据
- 查询本部门及其子部门数据
- 查询自定义部门范围数据
- 查询本人数据
特别说明
如上所述,要求数据权限的表 必须要有部门列和创建用户列,也就是每一条数据关联到一个部门和创建人信息
# mapper 自定义方法使用
提示
Mapper 查询参数中带一个 空的 DataScope 对象 即可完成数据权限过滤功能,会根据当前用户角色自动匹配对应的过滤规则
@Override
public IPage getUsersWithRolePage(Page page, UserDTO userDTO) {
return baseMapper.getUserVosPage(page, userDTO, DataScope.of());
}
2
3
4
# mybatis-plus 扩展方法
- SelectListByScope(DataScope.of())
- SelectPageByScope(DataScope.of())
// 指定 datascope func 类型为 count 聚合函数
- SelectCountByScope(DataScope.of().func(DataScopeFuncEnum.COUNT))
2
3
4
5
6
# 实现原理
- mybatis 拦截器,拦截处理参数列表带有 datascope 参数的 mapper 方法。
- 查询当前用户所属角色的数据权限配置
- 拼接一条新的 SQL, 就是对所有数据加一个部门过滤,参考下边源码处理
select * from (" + originalSqlStr + ") temp_data_scope where temp_data_scope." + scopeName + " in (" + join + ")";
2
public class DataScopeInnerInterceptor implements DataScopeInterceptor {
@Setter
private DataScopeHandle dataScopeHandle;
@Override
public void beforeQuery(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) {
PluginUtils.MPBoundSql mpBs = PluginUtils.mpBoundSql(boundSql);
String originalSql = boundSql.getSql();
Object parameterObject = boundSql.getParameterObject();
// 查找参数中包含DataScope类型的参数
DataScope dataScope = findDataScopeObject(parameterObject);
if (dataScope == null) {
return;
}
// 返回true 不拦截直接返回原始 SQL
if (dataScopeHandle.calcScope(dataScope)) {
return;
}
List<Long> deptIds = dataScope.getDeptList();
// 1.无数据权限限制,则直接返回 0 条数据
if (CollUtil.isEmpty(deptIds) && StrUtil.isBlank(dataScope.getUsername())) {
originalSql = String.format("SELECT %s FROM (%s) temp_data_scope WHERE 1 = 2",
dataScope.getFunc().getType(), originalSql);
}
// 2.如果为本人权限则走下面
else if (StrUtil.isNotBlank(dataScope.getUsername())) {
originalSql = String.format("SELECT %s FROM (%s) temp_data_scope WHERE temp_data_scope.%s = '%s'",
dataScope.getFunc().getType(), originalSql, dataScope.getScopeUserName(), dataScope.getUsername());
}
// 3.都没有,则是其他权限,走下面
else {
String join = CollectionUtil.join(deptIds, ",");
originalSql = String.format("SELECT %s FROM (%s) temp_data_scope WHERE temp_data_scope.%s IN (%s)",
dataScope.getFunc().getType(), originalSql, dataScope.getScopeDeptName(), join);
}
mpBs.sql(originalSql);
}
/**
* 查找参数是否包括DataScope对象
* @param parameterObj 参数列表
* @return DataScope
*/
private DataScope findDataScopeObject(Object parameterObj) {
if (parameterObj instanceof DataScope) {
return (DataScope) parameterObj;
}
else if (parameterObj instanceof Map) {
for (Object val : ((Map<?, ?>) parameterObj).values()) {
if (val instanceof DataScope) {
return (DataScope) val;
}
}
}
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# 分布式编号生成器
编码规则作为最基本的服务,需要具有以下基本能力:
全局唯一或单用户唯一。在订单系统等场景下要求全局唯一,在IM场景下,在单用户维度下保持唯一即可。 高性能,高可用。发号服务一般是最基础的服务,是业务系统最核心的环节,动辄每天亿级调用,希望无限趋近于100%的可用性,并且保证低延迟。 除了最基本的能力外,根据业务的特点,对发号器会有以下要求:
1.趋势递增。 大多数场景下,生成的ID需要在Mysql等RDBMS数据库存储,并且作为索引,一般使用B+树的存储结构,所以在ID的生成上,最好保证是递增的,这样可以提高写入的性能。
2.严格递增。排序,IM增量消息等场景,会根据消息的ID做一致性和可靠性保证,比如IM消息,会将本地存储的ID和服务端存储的ID做对比,发现落后于服务端之后就会拉取新消息。这个时候就要保证严格递增,不能回退,否则就会导致消息错乱。
3.ID防遍历。有些场景下,是需要避免ID被遍历的,否则造成内部信息的泄漏,比如如果活动ID是递增的,就可以通过脚本遍历活动信息,进行刷量,漏洞攻击等。或者是根据递增的订单号,就可以分析一天增加了多少订单,被竞争对手利用。虽然拿到ID后业务可以进行加密处理,但这无疑是对业务层提出了更高的要求,提高了风险。
1、2 和 3是矛盾的,做不到兼顾,所以一般使用不同的ID生成策略。
# 生成效果
全局生成唯一的 ID,适合定义业务流水编号例如
2023100500001
2023100500002
2023100500003
2023100600001
2023100600002
2023100600003
2
3
4
5
6
7
# 引入依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-sequence</artifactId>
</dependency>
2
3
4
5
# 配置规则
- 定义切片规则,例如相同日期递增
public class TestBizName implements BizName {
/**
* 生成名称
*/
@Override
public String create() {
return DateUtil.today();
}
}
2
3
4
5
6
7
8
9
10
设置发号器生成规则
@Configuration
public class SequenceConfig {
@Bean
public Sequence sequence(DataSource dataSource,
SequenceDbProperties properties) {
return DbSeqBuilder
.create()
.bizName(new BizName())// 定义切片规则
.dataSource(dataSource) // 注入数据源
.step(1000) // 每次获取数据的个数
.retryTimes(3) // 重试次数
.tableName("test_sequence") // 存储表名信息
.build();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 使用
@Autowired
private Sequence sequence;
sequence.nextNo()
2
3
4
# 特性
- 基于DB取步长,区间、序列号生成器
- 基于redis取步长,区间、序列号生成器
- 基于雪花算法,序列号生成器
# 数据脱敏使用
# 数据脱敏效果
参考例子: 用户列表 手机号字段 进行中间 4 位 替换成 ****
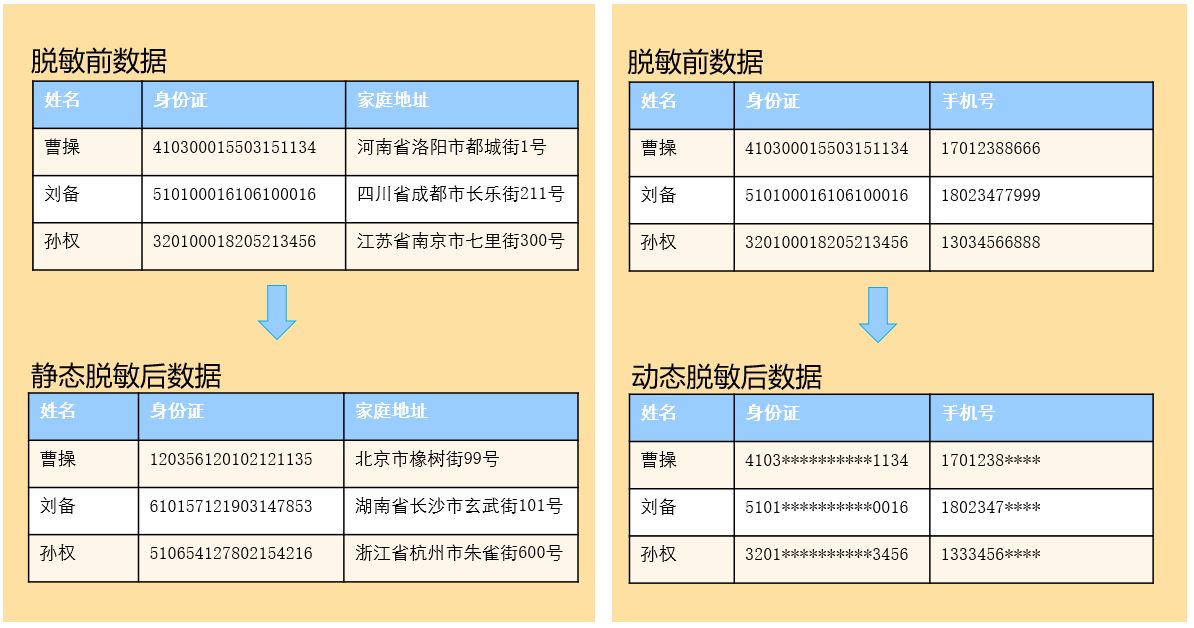
# 使用
只需要在对应 DTO 对象增加 @Sensitive
@Sensitive(type = SensitiveTypeEnum.MOBILE_PHONE)
@Schema(description = "手机号")
private String phone;
2
3
@Sensitive(type = SensitiveTypeEnum.ID_CARD)
@Schema(description = "身份证")
private String idCard;
2
3
# 支持的替换规则
/**
* 自定义 根据属性的指定哪几位打码
*/
CUSTOMER,
/**
* 用户名, 朱*华, 刘*
*/
CHINESE_NAME,
/**
* 身份证号, 440981********1234
*/
ID_CARD,
/**
* 座机号, ****1234
*/
FIXED_PHONE,
/**
* 手机号, 1/6****1234
*/
MOBILE_PHONE,
/**
* 地址, 广东********
*/
ADDRESS,
/**
* 电子邮件, t*****o@qq.com
*/
EMAIL,
/**
* 银行卡, 622202************1234
*/
BANK_CARD,
/**
* 密码, 永远是 ******, 与长度无关
*/
PASSWORD,
/**
* 密钥, 永远是 ******, 与长度无关
*/
KEY
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 系统缓存使用
# 说明
Spring Cache 进行扩展,支持到期删除、区分租户、全局缓存等操作
# 相关注解
spring boot cache 提供了一些注解方便做cache应用。
(1)@CacheConfig:主要用于配置该类中会用到的一些共用的缓存配置
(2)@Cacheable:主要方法返回值加入缓存。同时在查询时,会先从缓存中取,若不存在才再发起对数据库的访问。
(3)@CachePut:配置于函数上,能够根据参数定义条件进行缓存,与@Cacheable不同的是,每次回真实调用函数,所以主要用于数据新增和修改操作上。
(4)@CacheEvict:配置于函数上,通常用在删除方法上,用来从缓存中移除对应数据
(5)@Caching:配置于函数上,组合多个Cache注解使用。
# 作用和配置方法
 Spring Cache 学习笔记 (opens new window)
Spring Cache 学习笔记 (opens new window)
# 引入依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-data</artifactId>
</dependency>
2
3
4
5
# 缓存过期支持
执行对原有的 Spring Cache value 属性增加 #过期时间 即可
@Cacheable(value = VALUE_NAME#TTL, key = "#PARAMS")
// 例如: 过期时间 2 秒
@Cacheable(value = "USER#2", key = "#userId")
2
3
4
# 全局缓存
进行扩展对 Spring Cache 进行了区分,比如
- 租户有个 CacheName 为 XXX
- 租户有个 CacheName 为 XXX
在多租户情况下回自动租户,保存为 A:XXX / B:XXX
如何不区分租户: 例如租户查询这个功能, 多个租户查询的结果是一致的
只需要 在 CacheName 上增加 gl: 前缀即可
@Cacheable(value = "gl:tenant_details");
# 安全过滤使用
# 简述
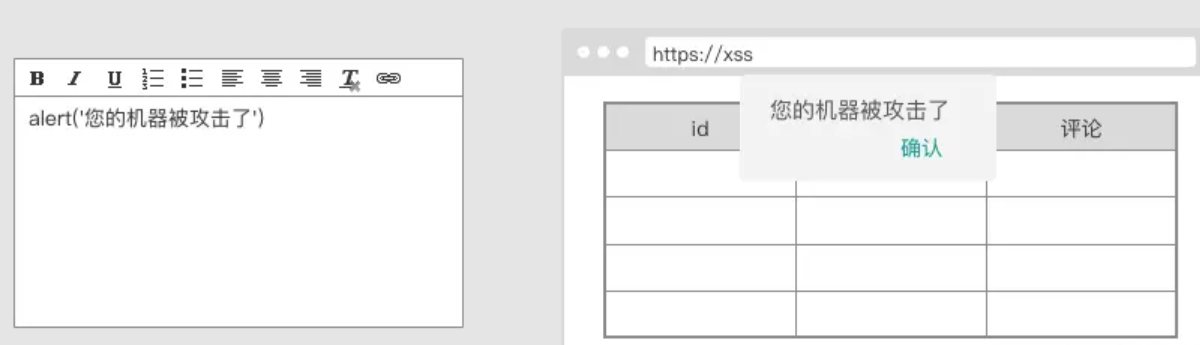
XSS(Cross Site Scripting)攻击全称跨站脚本攻击,为了不与 CSS(Cascading Style Sheets)名词混淆,故将跨站脚本攻击简称为 XSS,XSS 是一种常见 web 安全漏洞,它允许恶意代码植入到提供给其它用户使用的页面中。
# xss 攻击流程
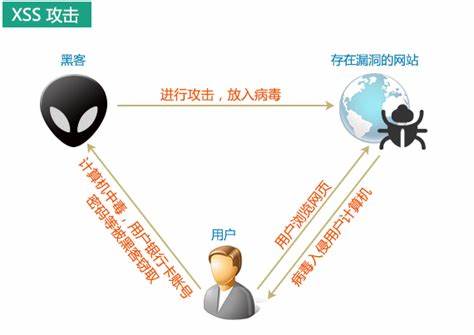
# xss 攻击示例
# XSS 过滤说明
- 对表单绑定的字符串类型进行 xss 处理。
- 对 json 字符串数据进行 xss 处理。
- 提供路由和控制器方法级别的放行规则。
# 引入依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-xss</artifactId>
</dependency>
2
3
4
# 配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| security.xss.enabled | true | 开启 xss |
| security.xss.path-patterns | 拦截的路由,必须配置 | /** |
| security.xss.exclude-patterns | 放行的规则 | 默认为空 |
@XssCleanIgnore 注解
可以使用 @XssCleanIgnore 注解对方法和类级别进行忽略。
# Excel 模块使用
# 说明
EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。 他能让你在不用考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。
# 特性
- 快速
快速的读取excel中的数据。 - 简洁
映射excel和实体类,让代码变的更加简洁。 - 大文件
在读写大文件的时候使用磁盘做缓存,更加的节约内存。
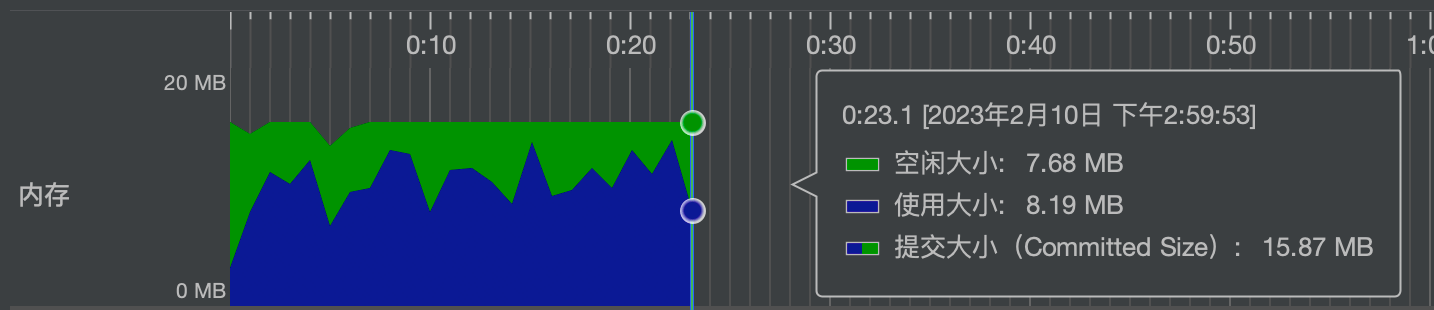
# 性能
16M内存23秒读取75M(46W行25列)的Excel
当然还有极速模式能更快,但是内存占用会在100M多一点
# 引入依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-excel</artifactId>
</dependency>
2
3
4
# 定义导入导出实体
public class UserExcelDTO {
@ExcelProperty("用户编号")
private Integer userId;
@NotBlank(message = "用户名不能为空")
@ExcelProperty("用户名")
private String username;
}
2
3
4
5
6
7
8
9
# 导出后端代码
- Controller 接口直接返回 List 元素即可,这里特别注意的时 接口上需要声明 @ResponseExcel 注解
@ResponseExcel
@GetMapping("/export")
public List<UserExcelDTO> export(UserDTO userDTO) {
return userService.listUser(userDTO);
}
2
3
4
5
6
# 导入后端代码
- Controller 接口使用 @RequestExcel 标记前端 excel 对应的实体列表, BindingResult 用来校验 实体 jsr303 校验失败结果
@PostMapping("/import")
public R importUser(@RequestExcel List<UserExcelDTO> excelVOList, BindingResult bindingResult) {
return userService.importUser(excelVOList, bindingResult);
}
2
3
4
5
- 获取校验结果 ,把不合法数据返回前端回显原因。 其中包括两种不合法(JSR303 不合法数据、自己个性化校验的)
List<ErrorMessage> errorMessageList = (List<ErrorMessage>) bindingResult.getTarget();
注意
当前下载模板 excel 无法打开时,提示文件损坏。 注意在 maven 中配置
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
<excludes>
<exclude>**/*.xlsx</exclude>
<exclude>**/*.xls</exclude>
</excludes>
</resource>
<resource>
<directory>src/main/resources</directory>
<filtering>false</filtering>
<includes>
<include>**/*.xlsx</include>
<include>**/*.xls</include>
</includes>
</resource>
</resources>
</build>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 动态数据源使用
# 说明
多数据配置,是基于 dynamic-datasourc (opens new window)实现,理论上支持此组件的全部功能。
# 简介
dynamic-datasource-spring-boot-starter 是一个基于springboot的快速集成多数据源的启动器。
其支持 Jdk 1.7+, SpringBoot 1.4.x 1.5.x 2.x.x。
# 特性
- 支持 数据源分组 ,适用于多种场景 纯粹多库 读写分离 一主多从 混合模式。
- 支持数据库敏感配置信息 加密 ENC()。
- 支持每个数据库独立初始化表结构schema和数据库database。
- 支持无数据源启动,支持懒加载数据源(需要的时候再创建连接)。
- 支持 自定义注解 ,需继承DS(3.2.0+)。
- 提供并简化对Druid,HikariCp,BeeCp,Dbcp2的快速集成。
- 提供对Mybatis-Plus,Quartz,ShardingJdbc,P6sy,Jndi等组件的集成方案。
- 提供 自定义数据源来源 方案(如全从数据库加载)。
- 提供项目启动后 动态增加移除数据源 方案。
- 提供Mybatis环境下的 纯读写分离 方案。
- 提供使用 spel动态参数 解析数据源方案。内置spel,session,header,支持自定义。
- 支持 多层数据源嵌套切换 。(ServiceA >>> ServiceB >>> ServiceC)。
- 提供 基于seata的分布式事务方案。
- 提供 本地多数据源事务方案。 附:不能和原生spring事务混用。
注意
注意动态数据源操作不要添加 @Transactional 注解,会导致数据源切换失效
# 引入依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-datasource</artifactId>
</dependency>
2
3
4
# 配置数据源
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master
strict: false #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
datasource:
master:
url: jdbc:mysql://xx.xx.xx.xx:3306/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver # 3.2.0开始支持SPI可省略此配置
slave_1:
url: jdbc:mysql://xx.xx.xx.xx:3307/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
slave_2:
url: ENC(xxxxx) # 内置加密,使用请查看详细文档
username: ENC(xxxxx)
password: ENC(xxxxx)
driver-class-name: com.mysql.jdbc.Driver
#......省略
#以上会配置一个默认库master,一个组slave下有两个子库slave_1,slave_2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 多主多从 纯粹多库(记得设置primary) 混合配置
spring: spring: spring:
datasource: datasource: datasource:
dynamic: dynamic: dynamic:
datasource: datasource: datasource:
master_1: mysql: master:
master_2: oracle: slave_1:
slave_1: sqlserver: slave_2:
slave_2: postgresql: oracle_1:
slave_3: h2: oracle_2:
2
3
4
5
6
7
8
9
10
# 使用 @DS 切换数据源。
@DS 可以注解在方法上或类上,同时存在就近原则 方法上注解 优先于 类上注解。
| 注解 | 结果 |
|---|---|
| 没有@DS | 默认数据源 |
| @DS("dsName") | dsName可以为组名也可以为具体某个库的名称 |
@Service
@DS("slave")
public class UserServiceImpl implements UserService {
@Autowired
private JdbcTemplate jdbcTemplate;
public List selectAll() {
return jdbcTemplate.queryForList("select * from user");
}
@Override
@DS("slave_1")
public List selectByCondition() {
return jdbcTemplate.queryForList("select * from user where age >10");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 开启动态数据源
// 注意此注解方案所有注解之上
@EnableDynamicDataSource
@xx
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
2
3
4
5
6
7
8
9
# 使用动态数据源查询
- Mapper 层 @Ds("#last") 固定写法,最后一个参数为指定数据源(必须有)
@Mapper
public interface DemoMapper extends BaseMapper<Demo> {
@DS("#last")
Map selectDs(String dsName);
}
2
3
4
5
6
- Service 层调用
@Service
public class DemoServiceImpl extends ServiceImpl<DemoMapper, Demo> implements DemoService {
@Override
public Object getByDs(Integer id) {
// 此处 dsName 为以上 gen_datasource_conf 加载数据源 name 字段
return baseMapper.selectDs("mom_core");
}
}
2
3
4
5
6
7
8
9
# 接口加解密器使用
# 说明
在一些安全性要求较高的项目中,我们希望客户端请求数据可以做到数据加密,服务器端进行解密。(单纯的 HTTPS 仍难以满足安全需要。)
# 引入依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-encrypt</artifactId>
</dependency>
2
3
4
# 配置加解密密钥
在对应微服务的 nacos 配置文件中进行配置
security:
api:
encrypt:
aes-key: 1234567812345678 # 注意必须为16位
2
3
4
# 普通 Get 请求
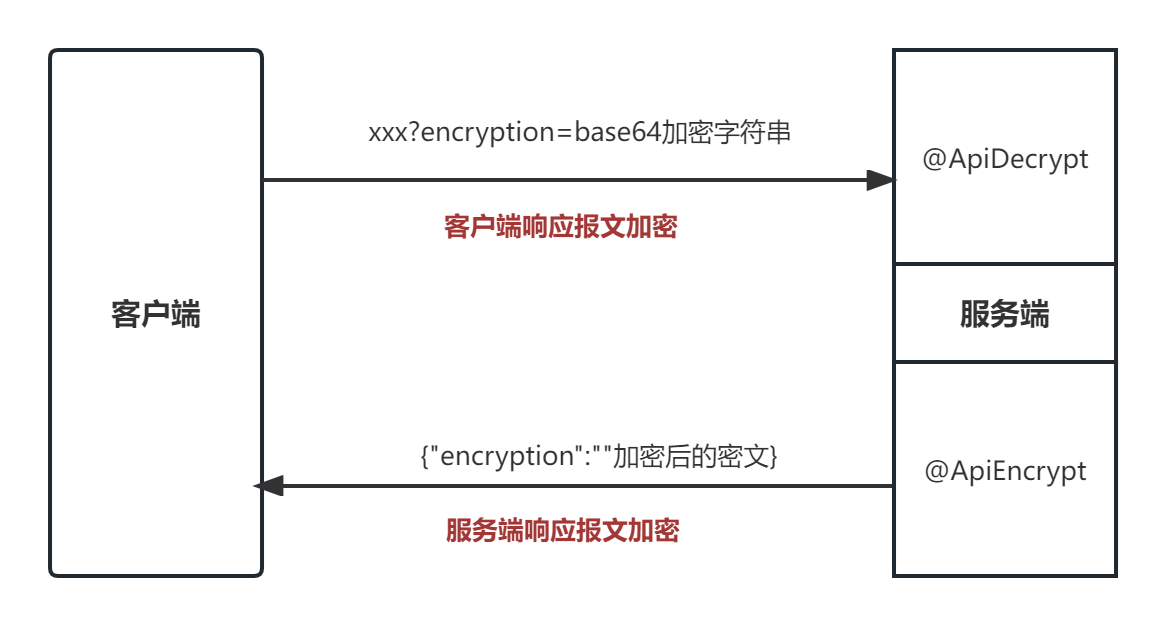
@ApiDecryptAes // 对请求进行解密 请求格式为 对请求进行解密 请求格式为 xx?encryption=base64密文
@ApiEncryptAes // 对接口结果进行加密输出 格式为 {"encryption":"加密后R"}
@GetMapping("/test")
public R test(String param) {
return R.ok();
}
2
3
4
5
6
7
# 通用 json body 请求

@ApiDecryptAes // 对请求进行解密 请求格式为 {"encryption":"base64密文"}
@ApiEncryptAes // 对接口结果进行加密输出 格式为 {"encryption":"加密后R"}
@PostMapping("/test2")
public R test2(@RequestBody String param) {
return R.ok();
}
2
3
4
5
6
# 前端处理
- 配置加密密钥 注意和上文后端加解密配置保存一致
todo 前端需AES 加密 密钥与后端一至
- axios 请求配置
request({
url: "xxx",
headers: {
"EncFlag": "true",
},
method: "get",
params: { xxx },
});
2
3
4
5
6
7
8
9
# 接口幂等使用
# 概述
幂等性原本是数学上的概念,即使公式:f(x)=f(f(x)) 能够成立的数学性质。用在编程领域,则意为对同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的。
幂等性是分布式系统设计中十分重要的概念,具有这一性质的接口在设计时总是秉持这样的一种理念:调用接口发生异常并且重复尝试时,总是会造成系统所无法承受的损失,所以必须阻止这种现象的发生。
实现幂等的方式很多,目前基于请求令牌机制适用范围较广。其核心思想是为每一次操作生成一个唯一性的凭证,也就是 token。一个 token 在操作的每一个阶段只有一次执行权,一旦执行成功则保存执行结果。对重复的请求,返回同一个结果(报错)等。
# 使用场景
务开发中,经常遇到重复提交的情况: 由于网络问题无法收到请求结果而重新发起请求 前端的操作抖动而造成的重复提交的情况
在交易系统中,支付系统这种重复提交造成的问题尤为明显: 用户在APP上连续点击多次提交订单,后台应该只产生一个订单 向支付系统发起请求,由于网络问题或者系统Bug问题导致重发,支付系统应该只做一次扣除操作
注意
声明幂等的服务认为,外部调用者会存在多次调用的情况,为了防止外部多次调用对系统的数据状态发生多次改变,需要将服务设计为幂等
# 幂等的不足
- 幂等是为了简化客户端逻辑,但是增加了服务提供者的逻辑和成本
- 幂等的使用需要根据具体场景具体分析
- 增加了额外控制幂等的业务逻辑,复杂了业务功能
- 将并行的功能转化为串行,降低了执行效率
# 引入依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-idempotent</artifactId>
</dependency>
2
3
4
# 配置 Redis 链接
默认情况下,可以不配置。理论是支持 redisson-spring-boot-starter 全部配置
spring:
cache:
type: redis
redis:
host: 127.0.0.1
port: 6379
2
3
4
5
6
7
# 接口配置
@Idempotent(key = "#key", expireTime = 10, info = "请勿重复查询")
@GetMapping("/test")
public String test(String key) {
return "success";
}
2
3
4
5
6
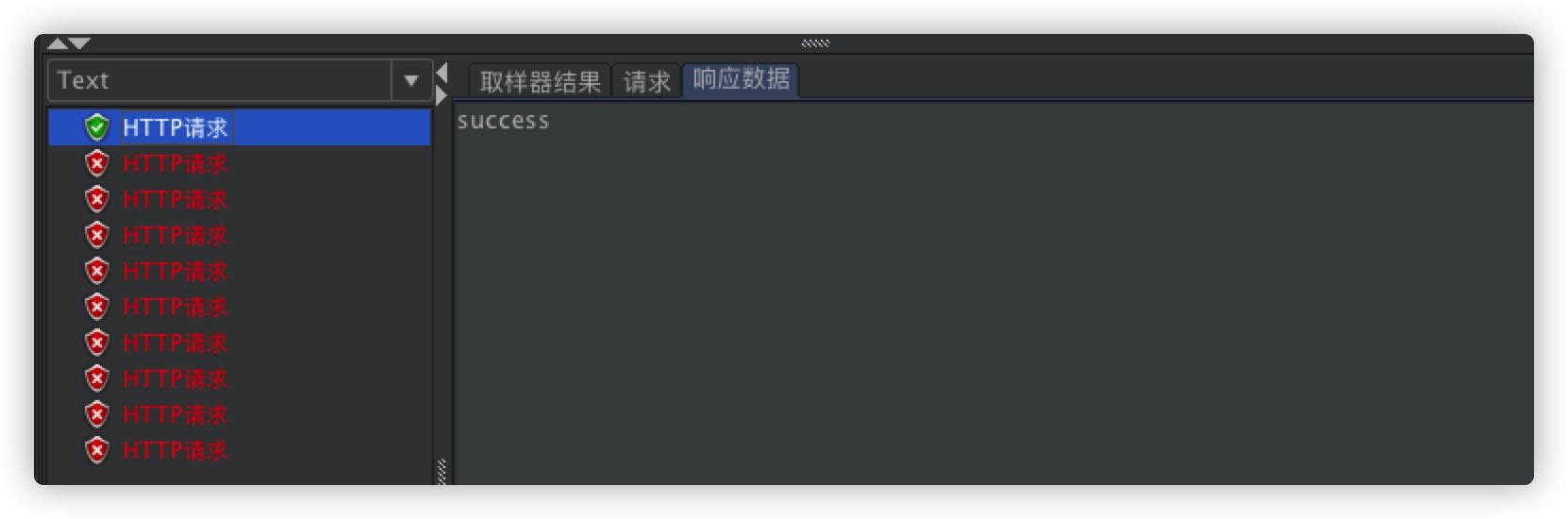
# 测试
10 个独立线程请求
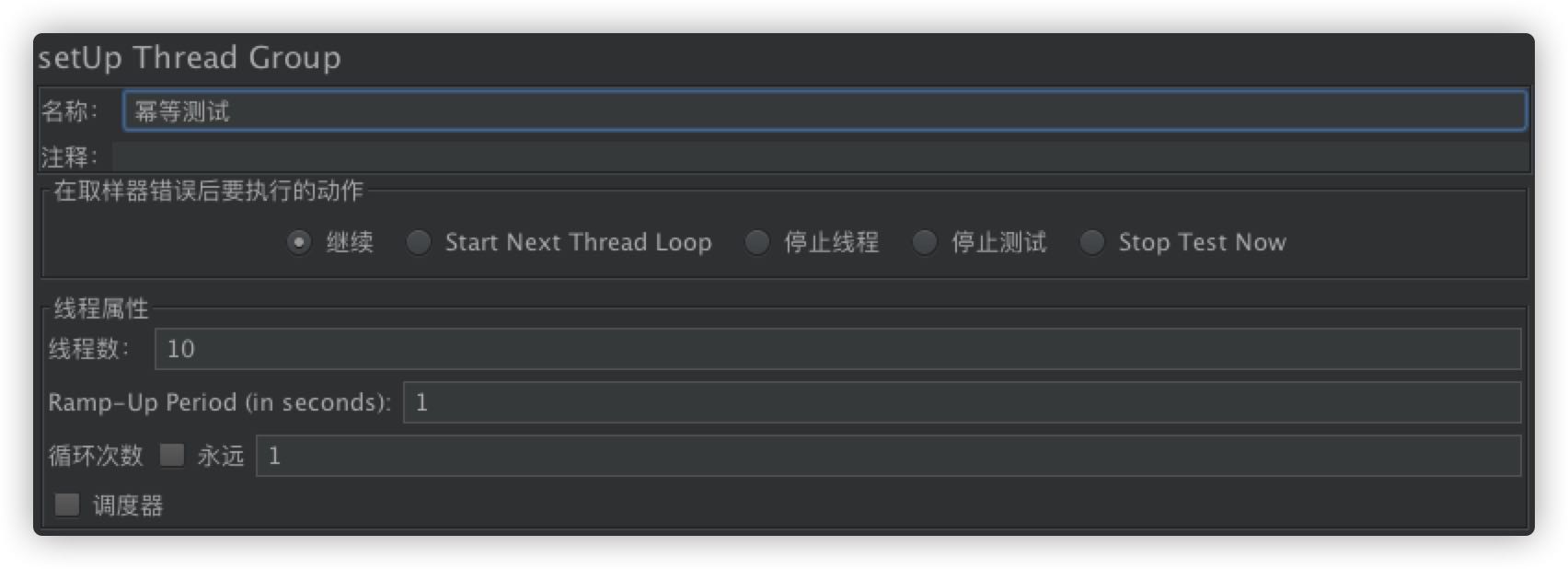
执行查看结果,10 个请求只会有一个成功
# 注解说明
key: 幂等操作的唯一标识,使用 spring el 表达式 用#来引用方法参数 。 可为空则取当前 url + args 做请求的唯一标识
expireTime: 有效期 默认:1 有效期要大于程序执行时间,否则请求还是可能会进来
timeUnit: 时间单位 默认:s (秒)
info: 幂等失败提示信息,可自定义
delKey: 是否在业务完成后删除 key true:删除 false:不删除
# 设计原理
请求开始前,根据 key 查询 查到结果:报错 未查到结果:存入 key-value-expireTime key=ip+url+args
请求结束后,直接删除 key 不管 key 是否存在,直接删除 是否删除,可配置
expireTime 过期时间,防止一个请求卡死,会一直阻塞,超过过期时间,自动删除 过期时间要大于业务执行时间,需要大概评估下;
此方案直接切的是接口请求层面。
过期时间需要大于业务执行时间,否则业务请求 1 进来还在执行中,前端未做遮罩,或者用户跳转页面后再回来做重复请求 2,在业务层面上看,结果依旧是不符合预期的。
建议 delKey = false。即使业务执行完,也不删除 key,强制锁 expireTime 的时间。预防 5 的情况发生。
实现思路:同一个请求 ip 和接口,相同参数的请求,在 expireTime 内多次请求,只允许成功一次。
页面做遮罩,数据库层面的唯一索引,先查询再添加,等处理方式应该都处理下。
此注解只用于幂等,不用于锁,100 个并发这种压测,会出现问题,在这种场景下
# 参数校验
# 为什么要做参数验证?
永远不要相信我们在后端接收到的用户数据。
- 防止恶意用户通过精心构造的参数破坏我们的系统
- 保证我们的业务有序进行 即使前端已经校验过,因为我们不能保证我们收到的请求都是由我们的前端程序发出,所以,后端必须进行参数校验!
# 如何进行参数校验
在日常的接口开发中,为了防止非法参数对业务造成影响,经常需要对接口的参数做校验,例如登录的时候需要校验用户名密码是否为空,创建用户的时候需要校验邮件、手机号码格式是否准确。靠代码对接口参数一个个校验的话就太繁琐了,代码可读性极差。
Validator框架就是为了解决开发人员在开发的时候少写代码,提升开发效率
提示
Validator校验框架遵循了JSR-303验证规范(参数校验规范), JSR是Java Specification Requests的缩写
Bean Validation 中内置的 constraint
JSR303 规范默认提供了几种约束注解的定义。具体如下表格:
| Constraint | 详细信息 |
|---|---|
| @Null | 被注释的元素必须为 null |
| @NotNull | 被注释的元素必须不为 null |
| @AssertTrue | 被注释的元素必须为 true |
| @AssertFalse | 被注释的元素必须为 false |
| @Min(value) | 被注释的元素必须是一个数字,其值必须大于等于指定的最小值 |
| @Max(value) | 被注释的元素必须是一个数字,其值必须小于等于指定的最大值 |
| @DecimalMin(value) | 被注释的元素必须是一个数字,其值必须大于等于指定的最小值 |
| @DecimalMax(value) | 被注释的元素必须是一个数字,其值必须小于等于指定的最大值 |
| @Size(max, min) | 被注释的元素的大小必须在指定的范围内 |
| @Digits (integer, fraction) | 被注释的元素必须是一个数字,其值必须在可接受的范围内 |
| @Past | 被注释的元素必须是一个过去的日期 |
| @Futuret | 被注释的元素必须是一个将来的日期 |
| @Pattern(value) | 被注释的元素必须符合指定的正则表达式 |
| Constraint | 详细信息 |
|---|---|
| 被注释的元素必须是电子邮箱地址 | |
| @Length | 被注释的字符串的大小必须在指定的范围内 |
| @NotEmpty | 被注释的字符串的必须非空 |
| @Range | 被注释的元素必须在合适的范围内 |
# 定义要参数校验的实体类
@Data
public class ValidDTO {
private String id;
@Length(min = 6,max = 12,message = "appId长度必须位于6到12之间")
private String appId;
@NotBlank(message = "名字为必填项")
private String name;
@Email(message = "请填写正确的邮箱地址")
private String email;
private String sex;
@NotEmpty(message = "级别不能为空")
private String level;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# @Validated和@Valid的区别
@Validated:
- Spring提供的
- 支持分组校验
- 可以用在类型、方法和方法参数上。但是不能用在成员属性(字段)上
- 由于无法加在成员属性(字段)上,所以无法单独完成级联校验,需要配合@Valid
@Valid:
- JDK提供的(标准JSR-303规范)
- 不支持分组校验
- 可以用在方法、构造函数、方法参数和成员属性(字段)上
- 可以加在成员属性(字段)上,能够独自完成级联校验
# 定义校验类进行测试
@RestController
@Slf4j
@Validated
public class ValidController {
@ApiOperation("RequestBody校验")
@PostMapping("/valid/test1")
public String test1(@Validated @RequestBody ValidVO validVO){
log.info("validEntity is {}", validVO);
return "test1 valid success";
}
@ApiOperation("Form校验")
@PostMapping(value = "/valid/test2")
public String test2(@Validated ValidVO validVO){
log.info("validEntity is {}", validVO);
return "test2 valid success";
}
@ApiOperation("单参数校验")
@PostMapping(value = "/valid/test3")
public String test3(@Email String email){
log.info("email is {}", email);
return "email valid success";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
这里我们先定义三个方法test1,test2,test3,
test1使用了@RequestBody注解,用于接受前端发送的json数据,
test2模拟表单提交,
test3模拟单参数提交。
注意,当使用单参数校验时需要在Controller上加上@Validated注解 , 否则不生效。
# 灰度路由
# 简介
灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度.
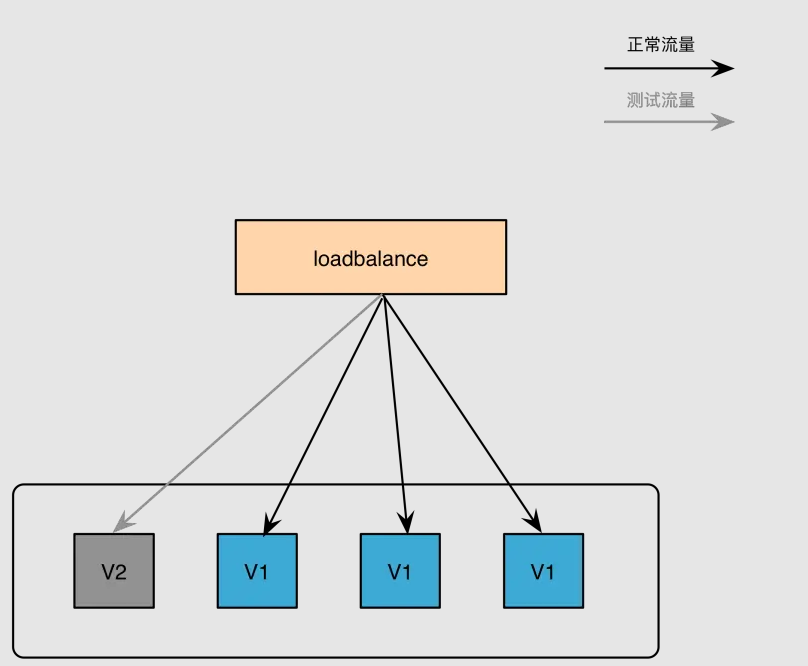
# 架构原理
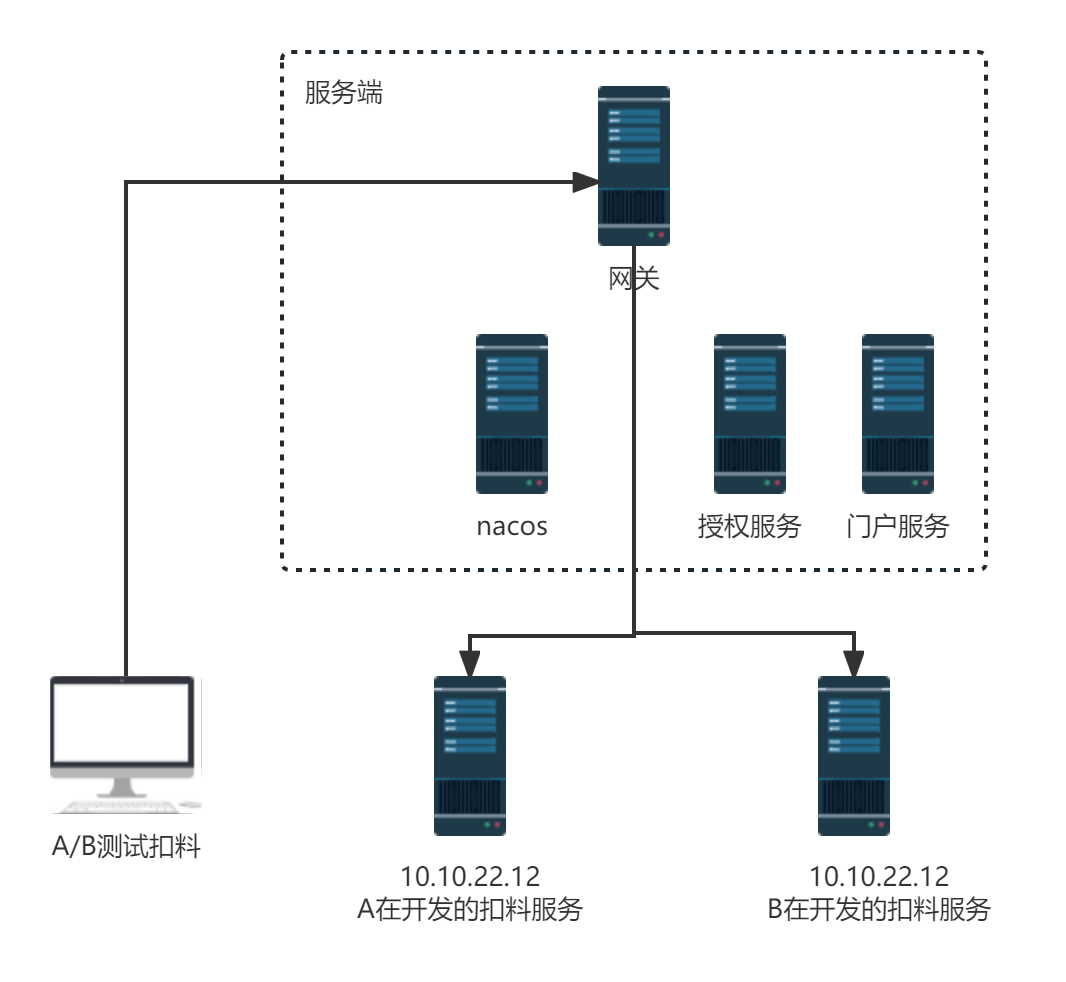
# 添加依赖
<dependency>
<groupId>com.sie.mbm.mom</groupId>
<artifactId>framework-gray</artifactId>
</dependency>
2
3
4
# 服务启动指定版本
- A 启动订单服务的时候增加 A 的版本号
java -Dspring.cloud.nacos.discovery.metadata.VERSION=A -Dserver.port=8002 -jar test-biz.jar
- B 启动订单服务的时候增加 B 的版本号
java -Dspring.cloud.nacos.discovery.metadata.VERSION=B -Dserver.port=8003 -jar test-biz.jar
# Nacos 查看是否有元数据信息
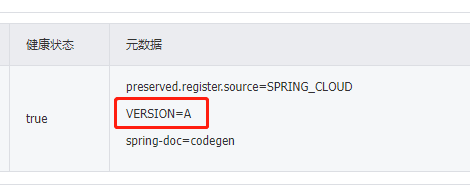
# 前端 axios
config.headers['VERSION'] = 'A' // 目标版本